7 Open Source LLM Text Generators You Need to Know About
Fine-tuned versions of open-source LLM models for text generation are coming out each day, and we have picked the seven we found most promising.

Enterprises, startups, or a hobbyist, whichever category you fall in, you would want to know about these LLM text generation models. After Meta released LLAMA2, the open-source community has been rolling out fine-tuned models that perform exceptionally well. We have hundreds of models coming out each month. Think of almost any use case and you can find an open-source fine-tuned model you can start using.
You might think why should you use a self-hosted model vs an API-based one? Well, self-hosted LLMs not only provide you with better transparency, data security, and control, but they are more customizable and cheaper at scale. Experts mostly agree that after the last cycle of innovation (i.e. from GPT3.5 to 4.0) where improved model reasoning came from making the training sets larger and larger (70B parameters & more) in turn making the models more and more computationally expensive to run, the next wave of improvement will stem from smaller models (i.e. 7B parameters) performing as well as the previous generation of 70B parameter models. These will be cheaper to run and provide answers faster expanding the range of suitable use cases and advancing the democratization of AI further.
Alright, enough about that, let me tell you about 7 exciting LLM text generators that were released or upgraded in the last 30 days, yes, that recently.
Let’s dive right in.
1- Zephyr-7b-alpha.Q4
This is the first LLM text generator on our list. It was released 9 days ago. Zephyr represents a collection of language models designed to function as useful assistants. The first model in this series is known as Zephyr-7B-α. It has undergone fine-tuning based on the Mistral-7B-v0.1. Mistral was trained using Direct Preference Optimization (DPO) on a combination of publicly available and synthetic datasets. It is more performant than the original mistral model but has less alignment, meaning it's more likely to provide problematic text when prompted to do so.
2- Sqlcoder2
SQLCoder is a model comprising 15 billion parameters. It is designed specifically for tasks related to natural language to SQL conversion. According to Defog.ai, the model creator, this model demonstrates superior performance in comparison to get-3.5-turbo based on their sql-eval framework. Moreover, it consistently surpasses the performance of all commonly used open-source models in this context.
SQLCoder's fine-tuning process is built upon the foundation of the base StarCoder model.
When fine-tuned with a specific schema, SQLCoder even surpasses the capabilities of Gpt-4.
3- Mythalion-13B
This model is based on Llama2. This LLM is trained specifically to write fiction for entertainment. The creators warn that any other use is out of scope as it might create factually wrong or misleading text. This model is the result of a collaborative effort between PygmalionAI and Gryphe, blending the Pygmalion-2 13B model with Gryphe's Mythomax L2 13B model. It is available for unrestricted use, both commercially and non-commercially, in compliance with the Llama-2 license terms.
4- Mistral-7B-Instruct-v0.1
This LLM is a finetuned generative text version of the Mistral-7B-v0.1 model. It is trained on multiple conversation data sets that are publicly available. The creators have claimed Mistral 7B which is a 7.3B parameter model performs better on all benchmarks than Llama 13B. There is a hosted inference API available if you want to check it out quickly. This model is intended to demonstrate ease to fine-tune the base model for any task.
5- Collectivecognition-v1.1-mistral-7b.Q8_0
Collective Cognition v1.1 is a cutting-edge model fine-tuned using the Mistral approach. It stands out for its remarkable performance, surpassing the capabilities of many 70B models on the TruthfulQA benchmark. It will come as a surprise that it was trained on just 100 data points on the data from the Collective Cognition website. This promises a substantial improvement in results with dataset expansion.
6- Dolphin 2.1 Mistral 7B
This text-generation LLM model was released 9 days ago by Eric Hartford. This a16z sponsored model is derived from mistralAI. It is suitable for both noncommercial and commercial use. It has been trained on the Dolphin dataset, which is an open-source of Orca by Microsoft. It is an uncensored model as the dataset was filtered to remove any bias or alignment. It is suggested by the creator to add an alignment layer before using the said model as a service.
7- ToRA-code-13B-v1.0-GGUF
Released 5 days ago, this model is trained on ToRA-Corpus 16k. These Tool-Integrated Reasoning Agents are focused on solving mathematical reasoning problems. They achieve it by interacting with tools like symbolic solvers and computation libraries. It is the first open-source model to have over 50% accuracy on the math dataset. It is at par with GPT-4 in regards to solving problems with programs and outperforms the CoT results of GPT-4 (51.0 vs. 42.5).
Hosting the LLM text generators on Codesphere
To use these LLM text generators using Codesphere, you need to follow these simple steps.
Start with creating a workspace in Codesphere and clone this repository or choose the ready-to-use template.
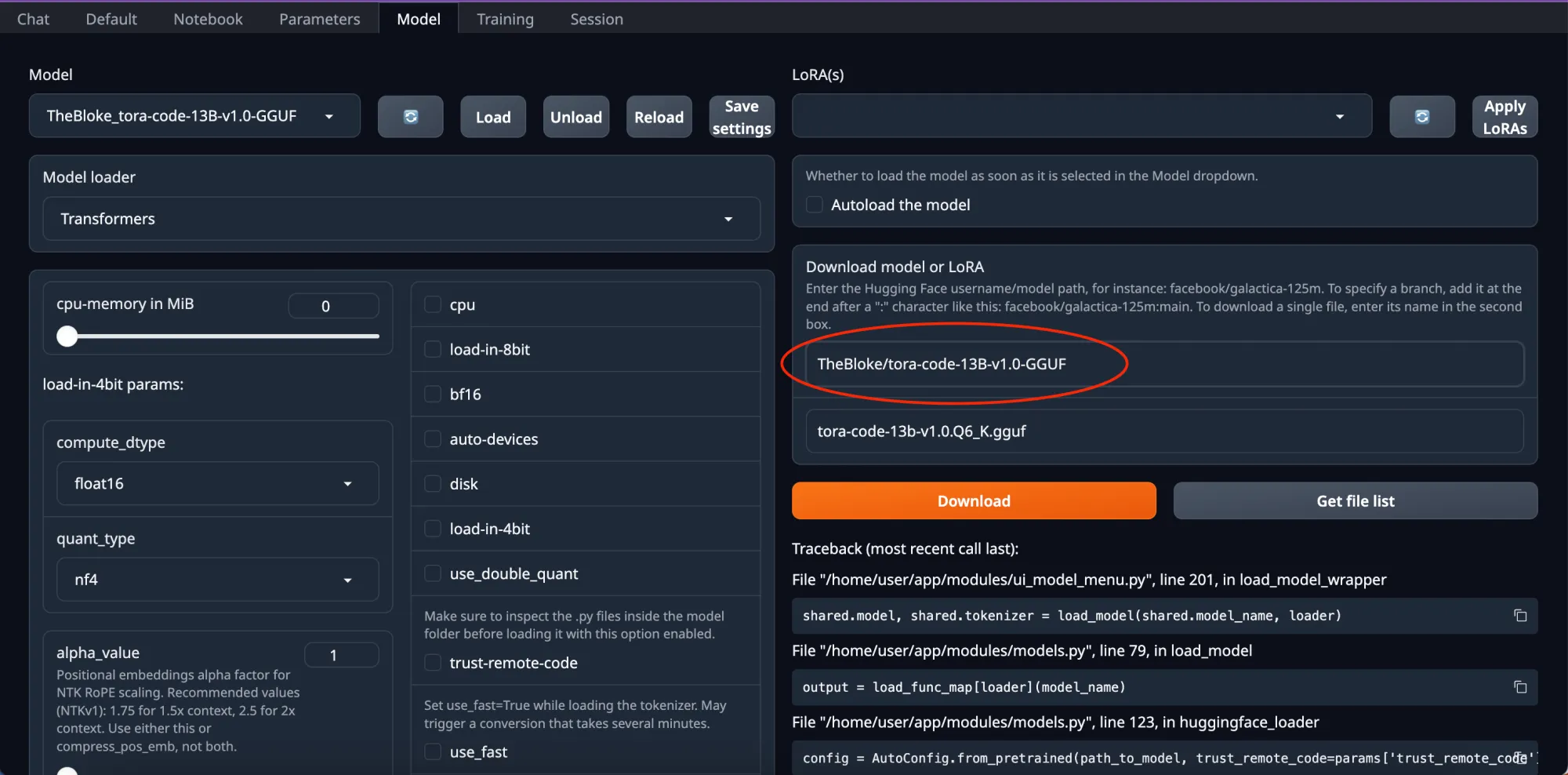
Next, you need to go to HuggingFace and click on a model you want to try.
Copy the slug and paste it into the circled box.
In the files and versions on HuggingFace, you can choose whichever version you prefer. Click it and paste it in the box highlighted.
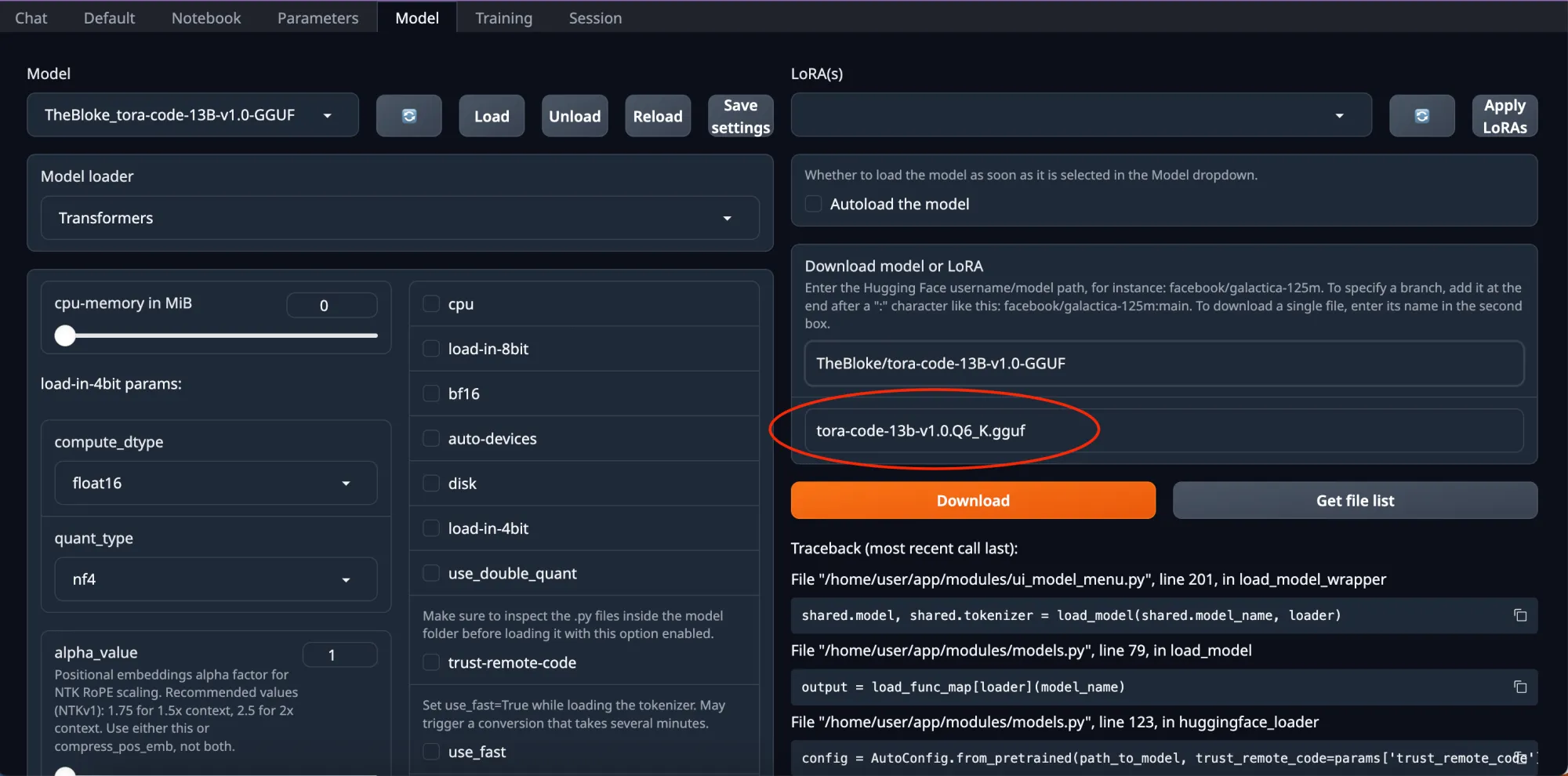
Click download and then refresh the page. You can then choose the model from the “Model loader” drop-down and click load.
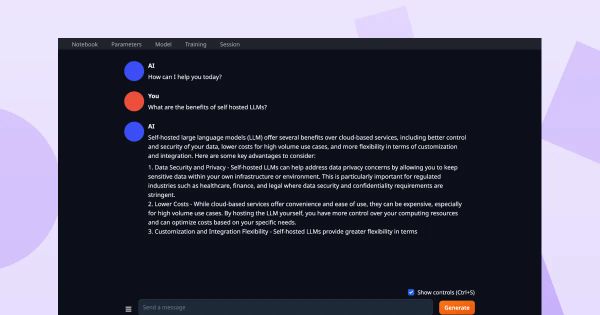
Your model is ready to use, go to the chat window and start using it.
Which text-generating LLM would you prefer?
The open-source models are better than ever and perform better than their API-based counterparts in some instances. I had a lot of fun using all these text-generating models and would love to know which one you like the best.
If you face any problem hosting these on Codesphere, get in touch.
