From first click to prompt output in 1m38s - Running Llama2 in Codesphere
Learn how to get your very own ChatGPT clone up and running in under two minutes. In this tutorial we show you how to run Llama2 inside of Codesphere.

Table of Contents
I was curious about running my own LLM inside a Codesphere workspace. I wondered if it would work well and be fast enough on our CPUs. It turned into one of the most exciting projects I've worked in recent weeks.
Meta has made their Large Language Models, Llama1 & Llama2, available to the public, including the pre-trained chat versions. This is different from OpenAI's approach. In tests, they perform similarly to GPT3.5 and GPT4, but they respond faster than GPT4.
These models come in different sizes, based on how many parameters they were trained on. Typically inference for LLM's is run on GPU instead CPU processors because these computation are very memory intense and GPU's have a clear edge there. GPU servers are costly and not as easily available as CPU servers. Codesphere provides free shared and dedicated GPU plans navigate to https://ai.codesphere.com/ to sign up for the open beta.
Therefore today we are going to test if we can still run the smaller model (trained on 7 Billion parameters) on a CPU based server inside of Codesphere. Since we know it will challenging to get a smooth response, we are going with our pro plan, providing 8 state of the art vCPUs, 16GB RAM and a 100GB of storage.
Getting Llama2 running on Codesphere is actually very easy thanks to the amazing open source community, providing C++ based wrappers (llama.cpp) and huggingface offering pre-compiled and compressed model versions for download.
It is actually so easy that I decided to do a timed run. From the click to create a new workspace button to the first chat response took 1 minute 38 seconds. It really blows my mind. Let's take a look how it's done inside of Codesphere.
If you still need to create a Codesphere account now is as good a time as any. If your machine is strong enough this tutorial will also work locally (at least for Linux & MacOS with small adjustments).
Zero config cloud made for developers
From GitHub to deployment in under 5 seconds.
Review Faster by spawning fast Preview Environments for every Pull Request.
AB Test anything from individual components to entire user experiences.
Scale globally as easy as you would with serverless but without all the limitations.
Step 1: Create a workspace from the Llama.cpp repository
To begin, log in to your Codesphere account. Next, locate and click on the "create new workspace" button. Finally, paste the provided information into the repo search bar located at the top.
https://github.com/ggerganov/llama.cppNext you'll want to provide a workspace name, select the pro plan and hit the start coding button. This plan is 80$/m for a production always on plan and 8$/m for a standby when unused deployment mode. Renting a GPU usually costs over 1000$/m, so 80$/m seems like a good deal.
Step 2: Compile the code
Open up a terminal and type:
makeThis command will compile the c++ code to be readable for Linux. The Llama.cpp repository contains a Makerfile that tells the compiler what to do.
Step 3: Download the model
First type cd models in the terminal to navigate to the folder where Llama.cpp expects to find the model binaries. There are a wide variety of versions available via hugging face, as mentioned we are picking the 7b params size and opt for the pre-trained chat version of that.
There are about 10 options for this specification. Choose the one that fits your needs. We recommend checking out this repository for helpful explanations and models: https://huggingface.co/TheBloke/CodeLlama-7B-Instruct-GGUF.
In the models directory run this command and replace the model name with the flavour that suits you best:
wget https://huggingface.co/TheBloke/CodeLlama-7B-Instruct-GGUF/resolve/main/codellama-7b-instruct.Q5_K_M.ggufStep 4: Run your first query
Now we can ask our very own chatbot the first question. Navigate back to the main directory with cd .. and then run this command from the terminal:
make -j && ./main -m ./models/codellama-7b-instruct.Q5_K_M.gguf -p "Why are GPUs faster for running inference of LLMs" -n 512It will take a few seconds to load the 4GB model into memory. After that, you will see your Chatbot typing a response to your question in the terminal.
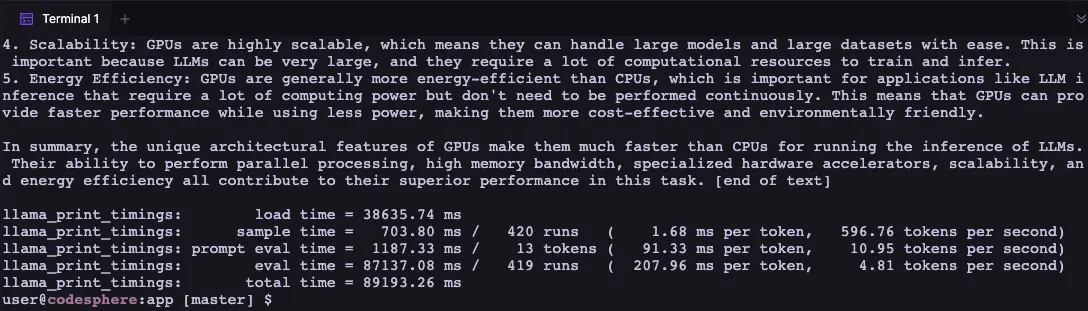
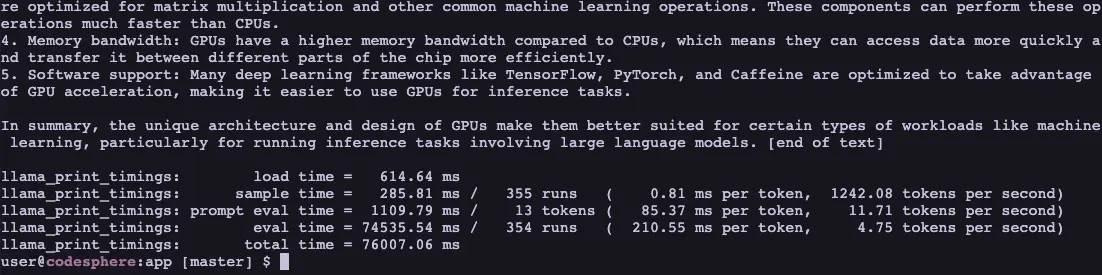
Once completed it will also print the timings, the initial load can take up to 30s but subsequent runs take less than 1s to start providing a response - also the speed is not quite as fast as interacting with chatGPT in the browser but it still returns around 4 words per second which is pretty good.
The images show the timing of the initial run vs. subsequent runs.
[Optional] Step 5: Getting the example chatbot web interface running on Codesphere
The llama.cpp repository comes with simple web interface example. This provides an experience closer to what you might be used to from ChatGPT.
Navigate to CI pipeline and click the Define CI Pipeline button. For the prepare stage enter make as command.
And for the run stage enter this command, making sure the model name point to the binary of the version you downloaded:
./server -m ./models/codellama-7b-instruct.Q5_K_M.gguf -c 2048 --port 3000 --host 0.0.0.0We need to set the port to 3000 and the host to 0.0.0.0, to expose the frontend in Codesphere.
Now you can run your prepare stage (which won't do anything if you previously ran make already via the terminal) but might be needed after workspace restarts.
Next run your run stage and click the open deployment icon in the top right corner. Now you and anyone you share the URL with can have chats with your self-hosted ChatGPT clone 😎

Let us know what you think about this! Also feel free to reach out to us if you are interested in getting early access to our GPU plans.
Happy Coding!
