Smart Chat RAG: Building Document-Aware Conversational AI
A modular chat system built on RAG principles enables transparent, document-grounded conversations. It uses semantic search, LLM inference, and preprocessing like OCR and table parsing for accurate responses.
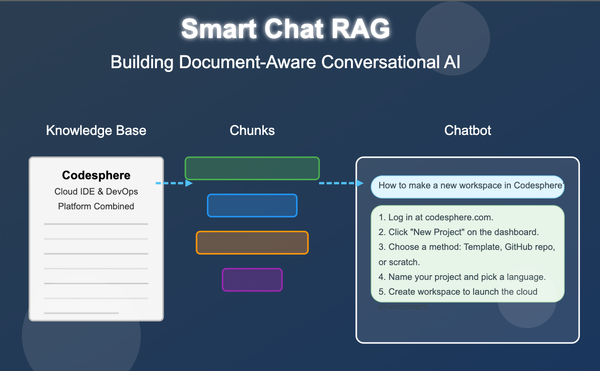

Creating a document-aware chat system is not merely about inserting a language model, it's about providing the correct context at the correct moment. This article discusses how to create a Retrieval-Augmented Generation (RAG) system that can respond to user queries that are in private documents. The architecture, critical components, and why preprocessing is as important as prompting are covered.
Contemporary businesses struggle with a severe challenge: making massive document libraries searchable, actionable, and accessible. Keyword searching is inadequate when users pose nuanced questions or have to integrate data from multiple documents. RAG systems come in here, bridging the disconnect between document handling and conversational AI.
Overview of a RAG System: Bringing Documents to Conversation
At an abstract level, this system allows users to ask queries to a document set and obtain responses through the integration of two advanced abilities:
- Semantic Retrieval — Retrieving the most appropriate fragments of information from a document set based on semantics instead of keywords. This entails converting documents and queries into vector forms that retain their semantic content.
- Generative QA — Answering questions on the basis of the retrieved data using a language model that is capable of synthesizing, summarizing, and explaining information in natural language. The model doesn't simply bring up information it reads and rewrites it to respond to the specific question.
The true magic occurs when these two are brought together, where retrieval offers the fact basis and the language model offers communicative smartness.
User Experience Flow: From Question to Answer
Here's how a user interacts with the system in detail:

Let's break down each stage of this interaction:
- Query Input: The user inputs a natural language query into the chat interface. This may be anything from "What is our company policy regarding remote work?" to "Summarize Q3 financial projections."
- Query Processing: The system converts the question to a dense vector representation via the same embedding model applied to the documents. This ensures queries and documents are being compared in the same semantic space.
- Similarity Search: The system indexes the vector database to retrieve document chunks whose semantics best align with the question. This is accomplished via cosine similarity or other vector distance metrics.
- Context Assembly: The context window is then assembled with the most pertinent chunks, usually coupled with other metadata such as the source and the hierarchy of documents.
- Response Generation: The assembled context and original question are fed into the language model that then generates an inclusive answer referencing the given data specifically.
- Reference Highlighting: The system labels what parts of the answer align to which of the source documents and highlights such references in the UI to help make things more transparent.
- User Feedback Loop: Users may click on references in order to view original documents, ask for further clarification, or narrow their question following the initial response.
This whole process generally only takes a matter of seconds, offering a smooth, conversational experience while ensuring the factual correctness of conventional document search.
System Architecture: The Technical Foundation
Under the hood, the data flows through these key components in a sophisticated pipeline:

Technical implementation includes a few important steps:
- Document Ingestion:
- Documents are ingested through a secure API, preprocessed according to document type (text or OCR for scanned documents).
- Content is chunked semantically and embedded with a fine-tuned model, and then stored in PostgreSQL.
- Query Processing:
- Queries are sanitized, encoded, and matched against document chunks using cosine similarity.
- Relevant chunks are chosen and combined with proper prompts.
- Response Generation:
- The LLM model produces the response with tuned parameters.
- Post-processing includes source attributions and formats the output.
Designed with modular services, the system supports flexible deployment.
Document Preprocessing: For Intelligent Retrieval
A well-designed chat system is only as smart as the data it's built on. Here's why preprocessing matters:
These preprocessing operations aren't optional, they're essential. Clean, well-structured input facilitates improved chunking, greater retrieval accuracy, and more reliable responses. Let's take a closer look at some of the most important methods:
Intelligent Document Chunking:
Instead of uniformly sized chunks, we maintain natural document boundaries:
- Paragraphs, sections, headers, and lists remain undamaged.
- Tables are treated as whole units.
- Overlapping chunks avoids information loss.
This yields higher retrieval accuracy and answer coherence.
Handling Structure:
Documents have rich structural features:
- Tables, lists, headers, footnotes, and citations are treated to maintain context and relationships.
- Preprocessing makes these features searchable and interpretable to the model.
For more detailed workflows, step-by-step guide and real-world examples, check out these related articles:
These techniques directly power the document preprocessing behind this chat system extracting structure and meaning from raw PDFs so users get accurate, context-aware answers.
Triggering the LLM: Context-Aware Instructions
Guiding the language model to produce precise and well-formatted responses from context-retrieved information is the final stage of the RAG pipeline. An effectively written system prompt keeps the model on track and honest.
Core system prompt:
"You are a helpful chatbot that truthfully answers questions based on the given context.
Answer with appropriate detail, but keep it concise.
Mention all relevant information from the context.
Avoid unnecessary phrasing at the beginning.
Ensure clear and readable formatting."
Prompt structure consists of several components. System instructions define the chatbot’s behavior. Context framing sets up the background for interpreting user questions. Retrieved document chunks provide factual grounding from the source data. Source attribution guidance ensures the output remains transparent and referenceable. The user query anchors the response to the user’s intent. Formatting rules define how the output should appear.
Over time, a few prompting lessons emerged. It's essential to clearly explain how to apply the context. Sorting sources by relevance helps streamline answers. Setting expectations for formatting and conciseness leads to better readability. Finally, ambiguity should be addressed with fallback instructions to avoid confusion.
These methods assist in generating reliable, context-aware, and readable outputs.
Technology Stack Overview
To support scalability, speed, and maintainability, the system is constructed on a lean technology stack optimized for document processing and retrieval-augmented generation.
- Database: PostgreSQL with pgvector
- Backend: FastAPI, Python
- Frontend: Svelte, Vite
- ML Model: LLaMA.cpp (4-bit quantized)
- Embedding: Fine-tuned SentenceTransformer
- Orchestration: Prefect
- OCR: Tesseract with custom post-processing
- Deployment: Codesphere
This configuration supports efficient processing of large document sets, responsive querying, and seamless integration of machine learning elements.
Conclusion:
Whether a RAG-powered chat system works or not relies on what goes on in the background. Good preprocessing, smart chunking, semantic recall, and thoughtfully crafted prompts all combine to make answers rooted, pertinent, and reliable.
This system combines those components to provide a chat experience that's accurate, clear, and manageable by design.
Because in clever chat the actual cleverness begins a long time before talking begins.
