Building an AI powered search in Node.js using Qdrant Cloud
Discover how to build an AI-powered search for your web application using Qdrant and Node.js, enhancing content discovery with vector databases and LLMs.


Introduction
Since the launch of ChatGPT, we've been seeing more and more use cases for LLMs reaching from helping with ideation to complex support agents connected to custom data bases.
In this article, I will talk about how I set up an AI powered search in Node.js. This can be used for any use case. In my case i connected it to the Codesphere blog, enabling an AI powered search.
What is Qdrant
In a nutshell, Qdrant provides vector databases, featuring a user-friendly API for managing collections of data points, querying, and searching.
My experience with vector databases began with Qdrant, which simplified an otherwise complex environment. It offers a JavaScript SDK, integrating seamlessly with existing Node.js projects to leverage the capabilities of large language models (LLMs).
All of this is tied together through Qdrant Cloud which essentially provides managed Qdrant databases for you to use and includes a free tier. It has a convenient graphical interface which can be used to look at the collections created.
Understanding Vector Databases
In more sophisticated applications involving large language models (LLMs) in some way, vector databases are often used to handle custom data. Unlike traditional databases that store data in tables and rows, vector databases use embeddings. These embeddings are lists of numbers representing data in a high-dimensional space, much more complex than a simple three-dimensional space.
The transformation of regular data into vector embeddings is carried out by trained LLMs. These models understand the context and semantics of the data, converting it into a vector that accurately represents its meaning in this multi-dimensional space. This allows for efficient processing and comparison of complex data, such as text or images, enabling more sophisticated and context-aware search capabilities.
The Workflow for my Blog Search
Having understood the basics about how a vector database works and how data can be converted into embeddings, the workflow itself is pretty simple:
- Create a collection
- Check which articles are already in the Qdrant database
- Create embeddings for missing articles
- Upload to Qdrant
With that, it is possible to create embeddings for search queries and search the collection in the database.
Setting Up Qdrant in JavaScript
Before diving into the specifics of building the AI-powered search, it’s crucial to understand how to set up Qdrant in a JavaScript (Node.js) environment. This setup forms the foundation upon which all the subsequent functionalities rely.
Qdrant Client Initialization
First, you’ll need to initialize the Qdrant client. This client acts as the bridge between your Node.js application and the Qdrant database, enabling you to interact with the database programmatically.
import { QdrantClient } from "@qdrant/js-client-rest";
const client = new QdrantClient({
url: 'https://[your-qdrant-instance-url]',
apiKey: "[your-api-key]"
});
Replace '[your-qdrant-instance-url]' and '[your-api-key]' with your Qdrant instance URL and API key. This setup assumes you have an account with Qdrant Cloud and have set up a database instance.
One thing to note is, that at least for me, I couldn't get the SDK to work with a local in memory setup of the database without using Docker. So keep in mind that you will either need Qdrant Cloud or a custom Docker image running locally with your database in it. Running a managed Docker image on Digital Ocean unfortunately didn't work for me either.
Installing Required Libraries
To fully leverage the capabilities of Qdrant and LLMs, you’ll need to install certain libraries. The @qdrant/js-client-rest library is used for interacting with the Qdrant API, and @xenova/transformers for processing text into vector embeddings.
npm install @qdrant/js-client-rest @xenova/transformers
This command installs the necessary Node.js packages into your project, allowing you to use the Qdrant client and the Xenova pipeline for text encoding.
Text Encoding with Xenova
The Xenova pipeline is a crucial part of transforming text data into vector embeddings. This is done through the encodeText function, which leverages a pre-trained model to process text.
import { pipeline } from "@xenova/transformers";
async function encodeText(text) {
const extractor = await pipeline("feature-extraction", "Xenova/all-MiniLM-L6-v2");
return await extractor(text, {pooling: "mean", normalize: true});
}With these initial setup steps, you're now ready to dive into creating and managing your AI-powered search functionality using Qdrant.
Following this setup guide, let’s delve into the four key steps of building the AI-powered search.
1. Creating a Collection with Qdrant
To kickstart the AI-powered search, the first task is setting up a collection in the Qdrant database. Think of a collection as a flexible and dynamic container for your data, specifically tailored for vector-based operations.
Function: recreateQdrantCollection
The recreateQdrantCollection function is our gateway to initializing this collection. It's here that we define the crucial parameters of our vector space, like its size and the distance metric, which are key to how our data will be interpreted and queried. The vector size will be determined by the LLM you're using for transforming your data into embeddings. I simply just ran an example conversion to get the right size.
async function recreateQdrantCollection(collectionName, vectorSize) {
console.log("Creating collection");
try {
await client.recreateCollection(collectionName, {
vectors: {
size: vectorSize,
distance: "Dot"
}
});
console.log(`Collection ${collectionName} created successfully`);
} catch (error) {
console.error(`Error creating collection ${collectionName}:`, error);
throw error;
}
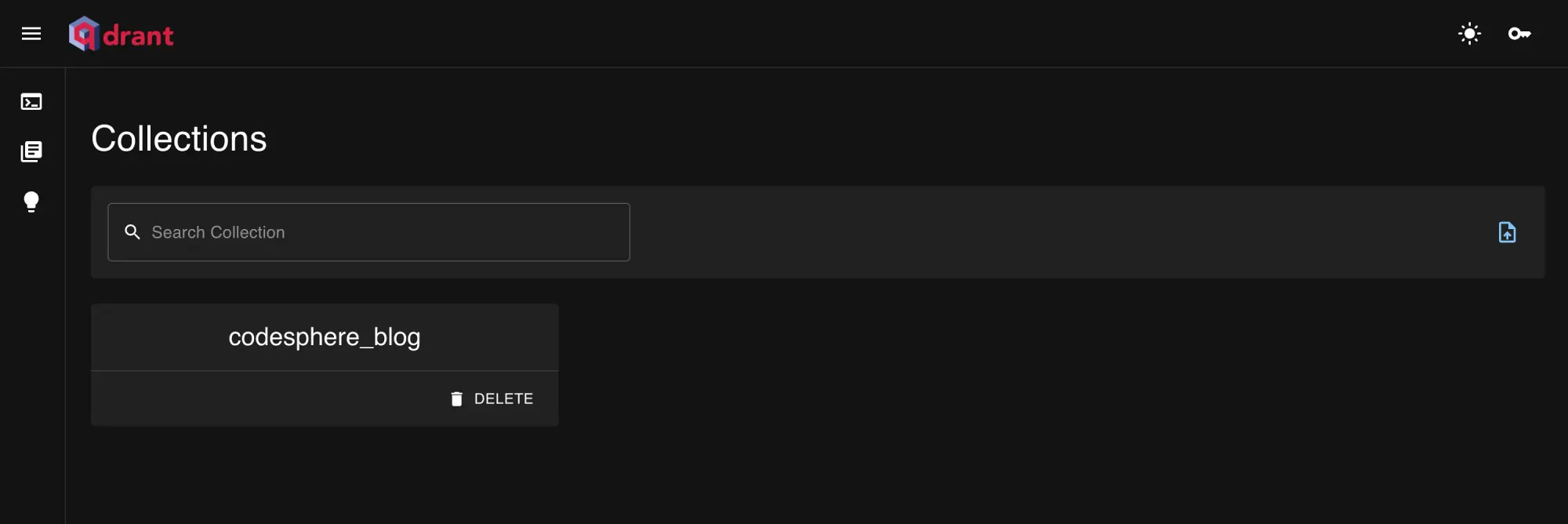
}As soon as the collection has been created, you will be able to see, access and manage it from the Qdrant dashboard:
2. Checking Existing Articles in the Database
Once the collection is set, it's important to ensure we're only adding new or updated content. This step is crucial for maintaining efficiency and avoiding redundancy.
Function: scrollThroughPoints
The scrollThroughPoints function comes into play here. It retrieves the IDs of all articles currently stored in the collection, giving us a clear picture of what’s already in there.
async function scrollThroughPoints(collectionName) {
let existingIds = [];
try {
let hasMore = true;
let scrollId = null;
while (hasMore) {
const response = await client.scroll(collectionName, {
limit: 1000,
with_payload: false,
with_vector: false,
scroll_id: scrollId,
});
response.points.forEach(point => existingIds.push(point.id));
scrollId = response.scroll_id;
hasMore = response.points.length > 0;
}
} catch (error) {
console.error(`Error scrolling through points in collection '${collectionName}':`, error);
}
return existingIds;
}
Keep in mind that there is a limit to set here which you should take a look at before running it. You can then use the data retreived from the database to check if your articles are already in the collection or not by comparing the ids.
3. Creating Embeddings for Missing Articles
For the articles that are not in the collection, we need to transform their textual content into a format that Qdrant can understand and work with – vector embeddings.
Function: encodeText
Here's where encodeText shines. It uses an LLM to convert text into vector embeddings, encapsulating the nuances and context of the content into a numerical form.
async function encodeText(text) {
const extractor = await pipeline("feature-extraction", "Xenova/all-MiniLM-L6-v2");
return await extractor(text, {pooling: "mean", normalize: true});
}4. Uploading to Qdrant
The final step in the setup is populating our Qdrant collection with these freshly minted embeddings.
Function: uploadDocuments
The uploadDocuments function takes these embeddings and carefully places them into our collection, making sure each piece of content is correctly represented and stored.
async function uploadDocuments(collectionName, documents) {
console.log("Uploading documents");
const points = documents.map(doc => ({
id: doc.id,
vector: doc.vector,
payload: doc.payload
}));
try {
await client.upsert(collectionName, { points });
console.log(`Documents uploaded successfully to collection '${collectionName}'`);
} catch (error) {
console.error(`Error uploading documents to collection '${collectionName}':`, error);
}
}
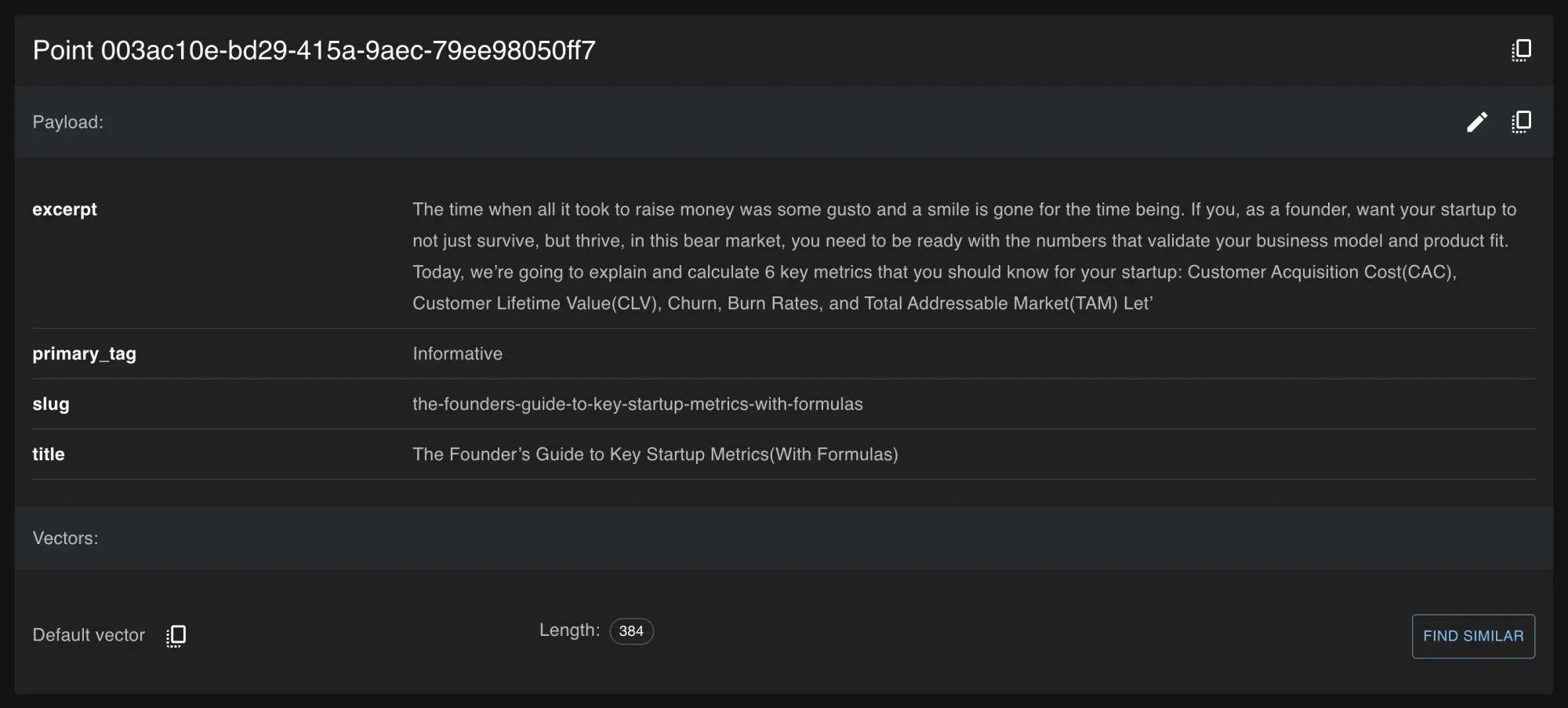
Keep in mind, that Qdrant does not support any kind of ids. The official documentation states that Qdrant supports using both 64-bit unsigned integers and UUID as identifiers for points.
In my case this was perfect, as our blog CMS (Ghost.io) provides a UUID for each article which I could just use to identify my points.
Implementing AI-Powered Search
After setting up our collection and populating it with blog articles, the next crucial step is to implement the search functionality. This involves querying the Qdrant database with a search vector and retrieving the most relevant articles.
Function: searchArticles
The searchArticles function is designed to perform this task. It takes a search query, converts it into a vector embedding (similar to how we processed our blog articles), and then uses this vector to search our Qdrant collection for the most relevant matches.
Here's an example of how this function could be structured:
async function searchArticles(query) {
const vector = await encodeText(query); // Convert query text to vector
try {
const searchResults = await client.search("codesphere_blog", {
params: {
hnsw_ef: 128,
exact: false,
},
vector: vector,
limit: 3, // Adjust limit as needed
});
console.log("Search results:", searchResults);
// Further processing of searchResults as needed
} catch (error) {
console.error("Error during search:", error);
}
}
// Example usage of searchArticles
searchArticles("AI powered search").catch(console.error);In this function, encodeText is used again to convert the search query into a vector. This vector is then passed to the client.search method, along with the name of your collection and other search parameters. The limit parameter determines how many results to return, and the hnsw_ef parameter is a configuration for the search algorithm (feel free to adjust these values based on your requirements).
With this setup, you can perform searches against your Qdrant collection, harnessing the power of vector similarity to find the most relevant articles for any given query.
The only thing that is left now is to put all of those pieces together in our production setup and connect it to the frontend. Since we're currently working on a more sophisticated version, I won't be going into detail on this but I think this should already give you a good overview about how you can use Qdrant to set up an AI powered search for your blog.
Conclusion
Qdrant made it very easy for me to get started in the vector database world. The JS SDK includes all necessary methods to interact with the database.
This in turn made is very easy to incorporate an AI-powered search into our blog. Now this could also be implemented into any other web application for wildly different use cases.
Whether for a blog, a knowledge base, or any other content-rich platform, this approach opens up new horizons in information retrieval and user engagement.
