Build an LSI Keywords Tool with Node JS
To make our short tutorial articles more SEO friendly we decided to add LSI keywords to them and to find those keywords we built an LSI keyword tool using Node JS.


Table of Contents
While rummaging through our blog the past few weeks, I noticed we have lots of short-form tutorial articles. I also gauged there isn’t a high chance of optimizing and ranking them for any high-density keywords or any specific long tail keyword with decent volume. So, I tried finding some LSI keywords and some long-tail keywords anyway to make them more SERP-friendly. Well, why put any effort into something like this? Because these are some interesting projects that need to be found in my opinion. So, what I did instead was, I found some LSI keywords and lightly sprinkled them throughout the article. To my surprise (or not) it actually worked and increased article clicks.
At Codesphere we actively strive to build our own tools, we even have our own Llama models running. So, I thought about building an application that provides LSI keywords based on the top ten Google articles. Let’s build one together.
Related Reading: Building an Email Marketing Engine
Web scrapping with Node JS
The first task of this project is to scrape Google Search Results and that would require us to install some libraries. We will use Express framework and Puppeteer for web scraping and rendering dynamic web pages. So here is what we will need to install:
1- Node JS
2- Puppeteer JS
3- Express JS
4- Fetch
Install Node JS using the links provided and for the rest, run these commands:
npm install puppeteer
npm install express
npm install fetchNow we are ready to start building our application. First, create an HTML page that takes input and makes a get request based on it to get the raw HTML data from Google. We will use Puppeteer to get the HTML data and parse it.
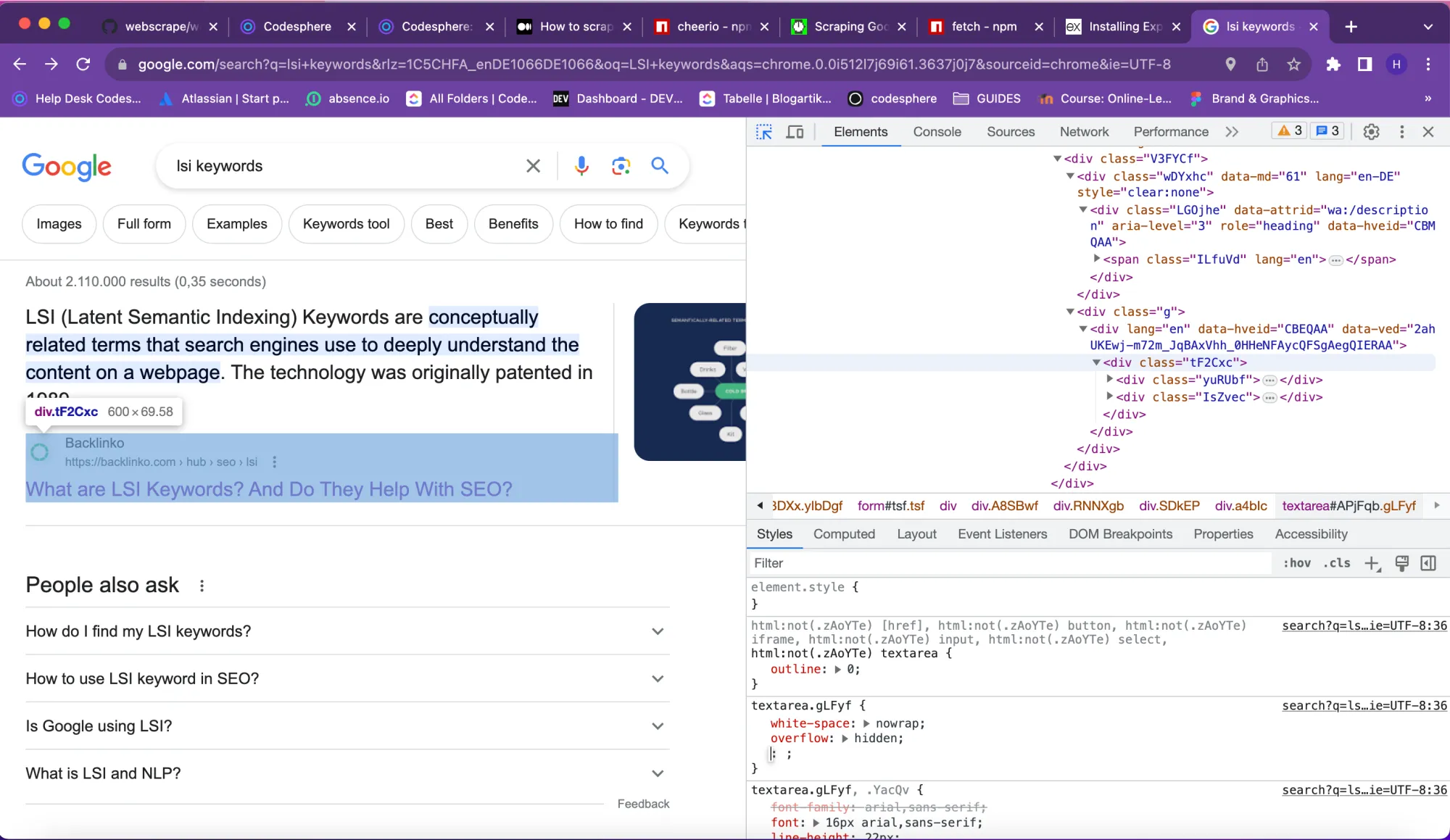
Since we are aiming to extract the title, URL and, content of the first ten articles we need to search HTML tags for them. Right click anywhere and choose the inspect option. It will look like the picture attached below.
The next step is to create an HTML page using the express framework to view the extracted data along with a fetch button that we will later use to communicate with openai API.
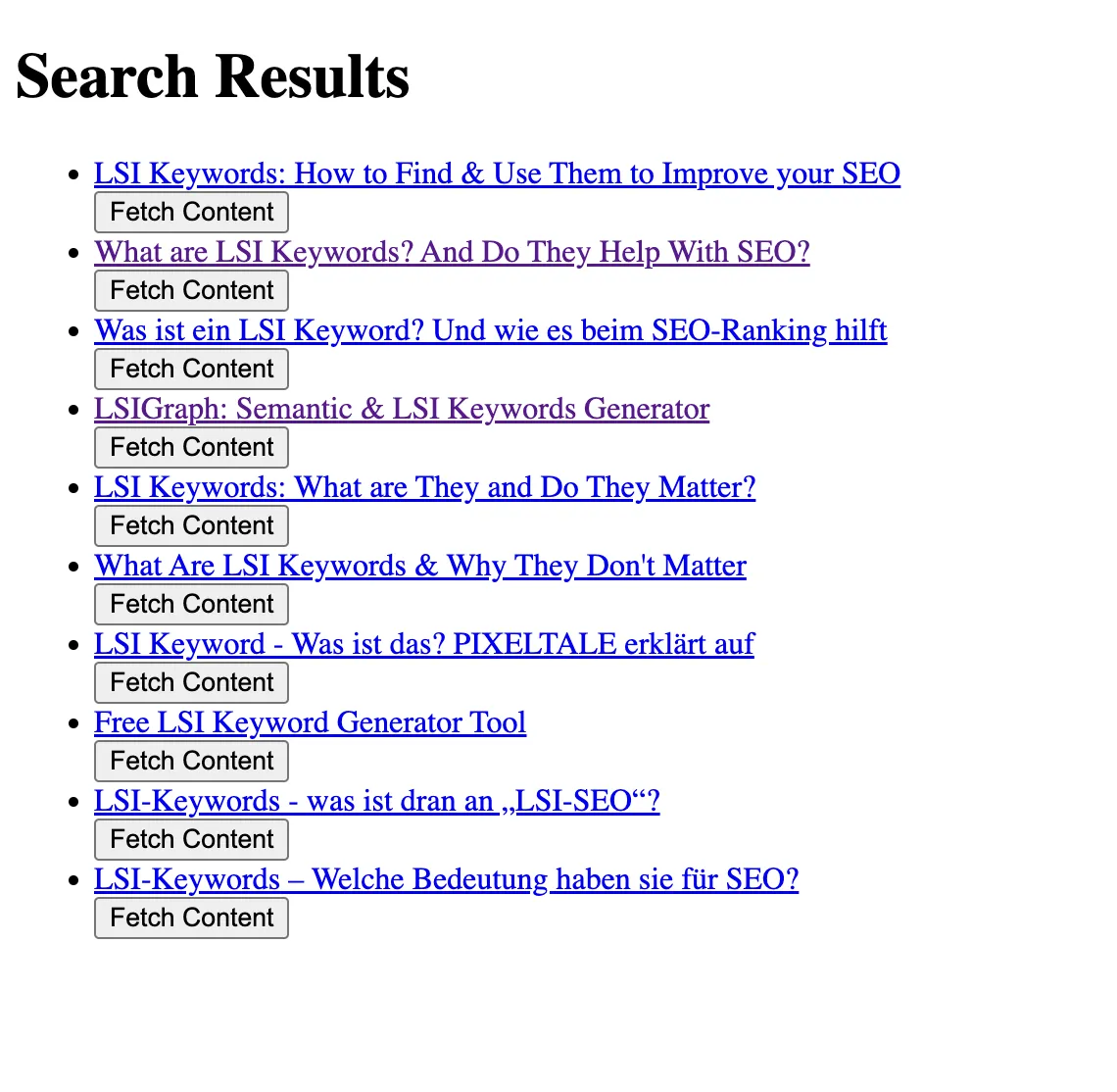
So, in your project create a views directory and in this directory create a file named results.ejs. Here is the code for this.
<!DOCTYPE html>
<html>
<head>
<title>Search Results</title>
</head>
<body>
<h1>Search Results</h1>
<ul>
<% searchData.forEach(result => { %>
<li>
<a href="<%= result.link %>" target="_blank"><%= result.title %></a><br>
<button onclick="fetchWebsiteContent('<%= result.link %>')">Fetch Content</button>
<div id="<%= result.link %>Content"></div>
</li>
<% }); %>
</ul>
<script>
async function fetchWebsiteContent(url) {
const contentContainer = document.getElementById(`${url}Content`);
contentContainer.innerHTML = 'Fetching content...';
try {
const response = await fetch(`/content?url=${encodeURIComponent(url)}`);
const data = await response.text();
contentContainer.innerHTML = `${data}`;
} catch (error) {
contentContainer.innerHTML = `Error: ${error.message}`;
}
}
</script>
</body>
</html>
Integrate the Openai API
We have a functioning web scrapping application now. To get LSI keywords based on this content, let’s use openai api. However, there are a limited number of tokens we can send as a query to openai and the content provided often exceeds the number of tokens allowed. So, to resolve this issue we will split the text and send it in iterations.
Upon clicking the fetch button on the “Search Result” page you will get LSI keywords based on the content of each article.
Congratulations now you have tens of relevant keywords to choose from.
Here is the complete code for this project:
const express = require('express');
const puppeteer = require('puppeteer');
const fetch = require('node-fetch');
const app = express();
const OpenAI = require('openai');
const path = require('path');
const port = 3000;
app.use(express.urlencoded({ extended: true }));
app.set('view engine', 'ejs');
app.set('views', path.join(__dirname, 'views'));
const openai = new OpenAI({
apiKey:'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',
});
//openai.baseURL = 'https://43882-3000.2.codesphere.com/v1'
app.get('/', (req, res) => {
res.send(`
<html>
<head>
<title>Google Search</title>
</head>
<body>
<h1>Google Search</h1>
<form action="/search" method="post">
<input type="text" name="query" placeholder="Enter your search query" required>
<button type="submit">Search</button>
</form>
</body>
</html>
`);
});
app.post('/search', async (req, res) => {
const query = req.body.query;
const lang = 'en';
try {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
const url = `https://www.google.com/search?q=${encodeURIComponent(query)}&hl=${lang}`;
await page.goto(url, {
waitUntil: 'networkidle2',
});
const searchData = await page.evaluate(() => {
const searchResults = [];
const resultContainers = document.querySelectorAll('.tF2Cxc');
for (let i = 0; i < resultContainers.length && i < 10; i++) {
const result = resultContainers[i];
const titleElement = result.querySelector('h3');
const linkElement = result.querySelector('a');
if (titleElement && linkElement) {
const title = titleElement.textContent;
const link = linkElement.getAttribute('href');
searchResults.push({ title, link });
}
}
return searchResults;
});
await browser.close();
res.render('results', { query, searchData });
} catch (e) {
res.send('Error: ' + e);
}
});
app.get('/content', async (req, res) => {
const url = req.query.url;
const query = req.body.query;
//try {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
await page.goto(url, {
waitUntil: 'domcontentloaded',
});
const websiteContent = await page.$eval('*', (el) => el.innerText);
// Working uptill now
// const aiModelEndpoint = 'https://42955-3000.2.codesphere.com';
// const encodedEndpoint = encodeURIComponent(aiModelEndpoint);
// const aiModelResponse = await fetch(encodeURIComponent, {
// method: 'POST',
// body: JSON.stringify({ content: websiteContent }),
// headers: { 'Content-Type': 'application/json' },
// });
// Our new code
const websiteContentList = websiteContent.split(/\s+/);
const lengthOfwebsiteContentList = websiteContentList.length;
const maxLimit = 4000;
var aiModelResponse = ''
var counter = 0;
for(var i = 0; i < lengthOfwebsiteContentList; i + maxLimit ) {
if (counter > 2) {
break
}
var limitedWebsiteContent = websiteContentList.slice(i, i + maxLimit).join(' ');
var completion = await openai.chat.completions.create({
messages: [{ role: 'user', content: 'Based on the following HTML, give a list of top 5 LSI keywords without numbering them\n'+ limitedWebsiteContent}],
model: 'gpt-3.5-turbo',
});
aiModelResponse = aiModelResponse + completion.choices[0].message.content;
counter = counter + 1;
}
//res.send(JSON.stringify(aiModelResponse))
const cleanedResponse = aiModelResponse.replace(/\n/g, '<br>').replace(',', '<br>');
res.send(JSON.stringify(cleanedResponse))
await browser.close();
//} catch (e) {
// res.send('Error: ' + e);
//}
});
app.listen(port, () => {
console.log(`Server is running on port ${port}`);
});Set it up in Codesphere
Log in to Codesphere and create a workspace. We can directly import the repository using our Git account. Now, we have to install all the dependencies here again using the same prompts we used earlier. We might also need to install some additional libraries like libnss3 and our application will be up and running.
Wrap up
Overall, this code sets up an Express server that provides a simple web interface for conducting Google searches and fetching content from URLs. It leverages Puppeteer for web scraping and OpenAI for generating content based on fetched web pages. The LSI keywords you get this way are very accurate and we have got results to prove it.
If you are interested in using self hosted LLama model, instead of openai head over to Codesphere Discord Community for more info.
