Self-hosted vs. API-based LLMs: Which One is Better?
LLAMA 2 has considerably bridged the gap between the quality and performance of open-source LLMS vs. the managed API-based models. Self-hosted LLMs are just as efficient and much more widely available now.


Large language models commonly known as LLMs are generative artificial intelligence models. These sophisticated AI models are trained on vast amounts of text data to understand and generate human-like text based on the input they receive. LLMs can perform a wide range of language-related tasks, including text generation, language translation, question answering, and more. They use deep learning techniques, particularly transformers, to capture complex linguistic patterns, making them highly versatile tools for natural language processing tasks.
If you have been searching for answers to questions like “How good are open-source LLMs? Or What are the best open-source LLMs”, your search ends today. We are going to discuss open-source vs. API-based LLMs regarding quality, security, customization, cost, and maintenance. So, let’s dive right in.
Significance of LLMs like LLAMA 2
The history of Large Language Models (LLMs) is a relatively recent but rapidly evolving one. One of the developments that hugely impacted NLP was the introduction of transformer architecture in 2017. Soon after that came BERT and GPT-1 in 2018. After that, both the open-source community and big tech realized the impact and importance of LLMs.
In 2020, GPT-3 was released which was trained on 175 billion parameters. The race to create bigger and bigger models started. However, there was a major problem that hindered the progress of the open-source community. The cost of training LLMs like GPT-3 was millions of dollars. The independent AI labs or open source community did not have enough means to compete with big tech companies. So self-hosted LLMs were not at par with API-based LLMs and businesses had no choice but to use models like GPT-3.5 or GPT-4.
However, that changed recently when LLAMA-2 was released by Meta and Microsoft collaboratively. It is allowed to be used for both experimental and commercial purposes. It has three versions available 7B, 13B, and 70B, the latter of which surpasses ChatGPT-3.5 in speed and efficiency as per these experiments.
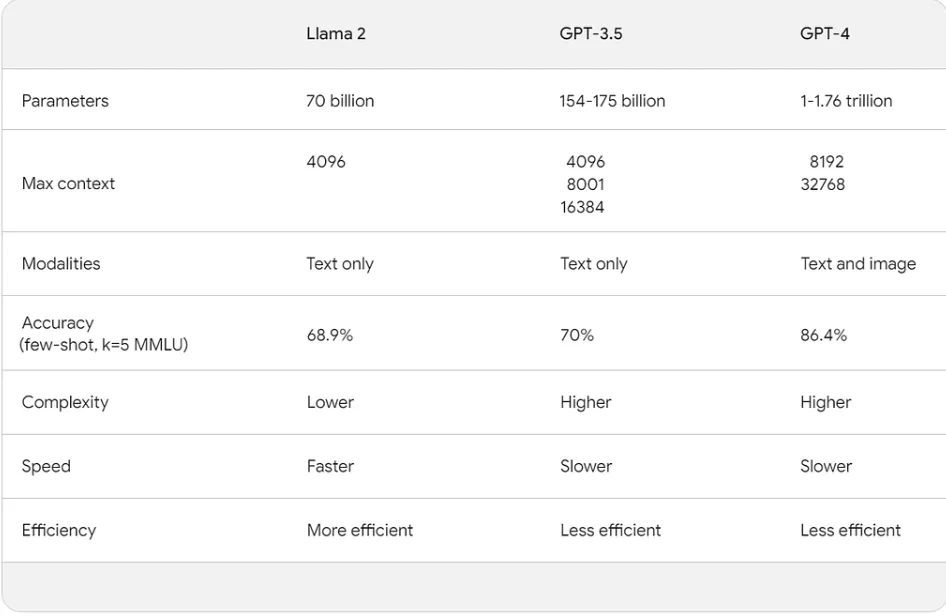
Comparison between Self-hosted vs. API-based LLMs
- Quality
The first thing to consider is the quality of the created content. Earlier, there was a huge quality difference between self-hosted and API-based models. However, the release of LLAMA2 has almost instantly bridged the quality gap between self-hosted and API-based LLMs. A quick look at the table shows that LLAMA 2 is at par with GPT 3.5 in main benchmarks.
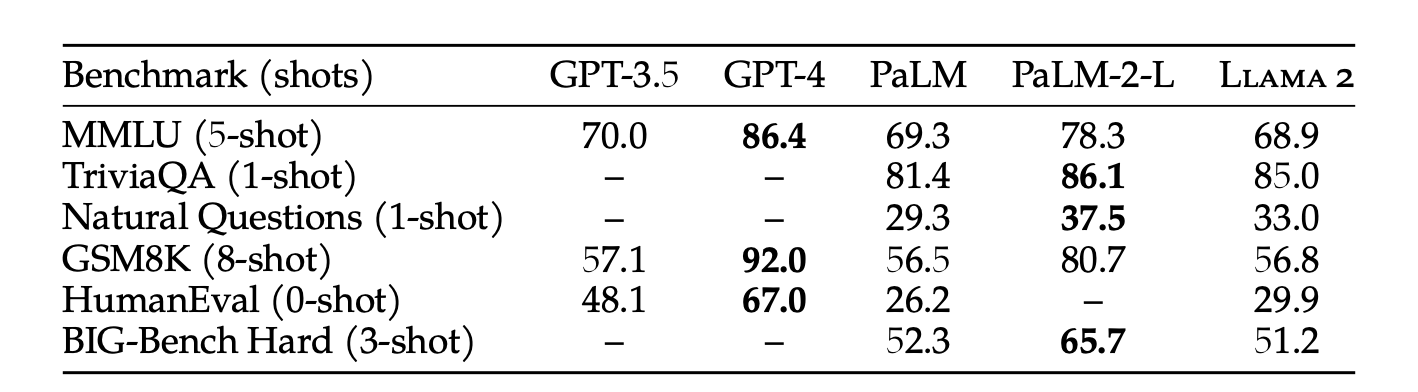
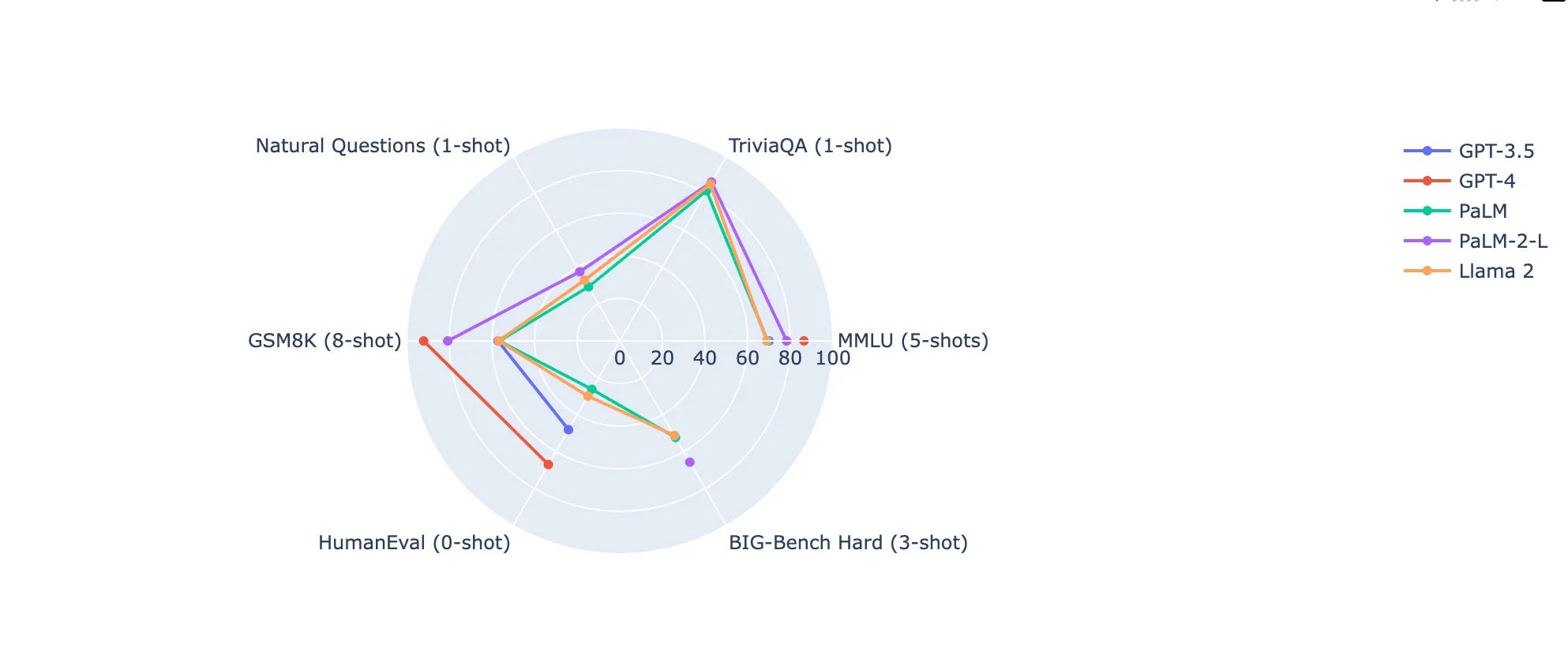
However, experiments run by Anyscale to check the factual accuracy of different LLM models revealed interesting results. The larger models like the 70B version of LLAMA-2 were at par with GPT-4 in understanding the prompt and generating results.
- Customization/fine-tuning
There is an interesting observation that smaller models trained on domain-specific large data sets can compete with generally larger LLMs in terms of performance. The good news is fine-tuning open-source models can be done with a relatively small budget and data. Interestingly, you can now find pre-trained models for a vast range of use cases. One such example is Vicuna which achieved more than 90% of Chat-GPT quality.
- Cost
One big advantage of using API-based models was the cost factor, especially at lower levels. However, the prices escalate quickly if you are using the services on a larger scale. For comparison, we are going to look at the cost of low and high-scale use.
ChatGPT is priced based on the number of tokens.
1 Token= ¾ words
The total number of tokens is determined by combining both the input prompts and the generated output. If we consider an input of 75 words and an output of 375 words. It makes 450 words in total. Each query of 450 words uses 600 tokens.
Assuming you get around 10,000 queries per day, let’s have a cost breakdown.
Input tokens used a day= 100*10,000=1000000
Output Tokens used a day= 500*10,000 = 5000000
We can see, that API-based models may have usage costs that can add up, especially for high-volume applications. On the other hand, most of the fine-tuned models are 7B or 13B models, which can be run on user-grade GPUs and cost less. How? We will talk more about this later.
- Development and maintenance
The narrative so far was that for API-based models you don't need to worry about model development, infrastructure setup, or deployment. You can typically integrate them into your applications with just a few lines of code. Whereas, it requires a significant investment in time, expertise, and resources. Whereas It might still be true for a small number of cases the open-source community has rolling out developments daily. As a result, you can easily find a pre-trained model for whatever use case you want. With such developments, having a dedicated ML team isn’t a necessity anymore for a self-hosted LLM. Using these open-source models is as easy as the API-based closed-source models.
Suggested Reading: Running Llama2 in Codesphere
- Transparency and Control
The transparency and control that you have with a self-hosted model is simply not possible with an API-based model. You are in charge of maintaining and updating your model and endpoint. This may take time and effort but saves you from unexpected issues. You don’t have to worry about being subjected to updates or changes that might break the application you have built on top of it. We have seen multiple mentions of deterioration of response quality with Api-based models, which is not the case when you self-host.
- Data Privacy and safety
Data autonomy and privacy is one of the biggest reasons for using self-hosted LLMs. The terms of use of openai mention they can use content from services other than their API. Enterprises that are concerned about proprietary data leaking to any API provider can manage where data gets stored and sent with these self-hosted options. One option is to use Azure OpenAI services, which are offered as private Azure hosting. However, watch out for the cost because if we take the same assumptions as before, hosting a 70 B LLAMA 2 will end up emptying $ 17,000+ out of your pocket.
Now, this may seem a little too much for small to medium-scale businesses. We have a solution for you, that will help you keep your data integrity intact without breaking your bank.
Hosting with Codesphere
Hosting your LLM model in Codesphere is extremely easy thanks to the open source community. We at Codesphere decided to do a time-run of how long it takes to set up a LLAMA 2 model and it came out to be 1 minute 38 seconds. If we talk about costs, as mentioned earlier most business use 7B or 13B domain-trained models.
You can run a 7B model on Codesphere with our pro plan that includes 8 vCPUs, 16GB RAM, and 100GB of storage. It costs only $80 per month with our normal workspaces and as low as $8 with our off-when-unused feature. Or it can be free. We just launched a free GPU plan, head over here to know the details: Host your custom LLM.
Even if you go for the largest 70B model, you self-host them with Codesphere. We offer dedicated and shared high-power GPU. You can pre-order these GPUs- via our demo process.
Future of LLMs
After the release of Llama2, one thing was evident. The monopoly of big tech is fading because these API-based LLMs are expensive and pose a threat to data privacy.
For example, right now, an average CPU that is in our computers and laptops takes around 2 minutes for one inference on Llama2. Another big revolution can be such that for each query it takes less than a second or maybe even a fraction of the second. This speed increase is such an important issue. Because it addresses a crucial barrier preventing many industries from adopting these models for production, or at least from doing so cost-effectively.
Moreover, the open-source community has hundreds and thousands of people contributing every day. On the other hand, big tech pays a limited number of people to do the same job. With the basic issue of the cost to train a model out of the way, we believe the open-source community will soon be at par if not surpass the quality of API-based models.
Conclusion
LLMs have made a huge impact on how we humans interact with technology. There was a large disparity between close-source and open-source technology at first but Llama2 opened up a wide array of possibilities, primarily through the process of fine-tuning the pre-trained model. One notable transformation is taking place within domain-specific industries. Each industry now has the opportunity to tailor the LLM to its unique requirements. Llama2 came out in May of this year and already there are several domain-specific variants, that perform better than vanilla GPTs on that particular domain. The choice of API-based vs. self-hosted LLM is still something we leave to you.
